Gender in a Gender Neutral Language: Gendered Language Use in Turkish Twitter Content
This piece was originally written and defended as my final BA research project for my degree in Middle Eastern Studies in Tallinn University in Spring 2020. Supervised by Sevda Özden and Sandra Peets.
Abstract
The aim of this paper is to analyse the frequencies of gendered and gender-neutral terms of person reference in Turkish using a corpus of Twitter data containing 107,990 tweets in Turkish and their metadata. Tweets and the profile descriptions, names and usernames of the tweeters were analysed for frequencies of a chosen list of words including gender-neutral, masculine and feminine terms of general person reference (such as “person” or “woman”) as well as a list of masculine and feminine terms referring to specific types of people (such as “actor/actress” or “prince/princess”) and compared. The results indicated a strong preference for gender-neutral terms, as well as a prevalence of gender stereotypes and their influence on vocabulary choice. Among general terms of person reference, feminine terms like ‘woman’ and ‘girl’ were much more frequent than their masculine counterparts, supporting other findings (e.g. by Braun, 2001) that femaleness is more frequently specified while maleness is a default state that does not need to be mentioned. Frequency differences between masculine and feminine terms describing occupations mirrored gender stereotypes for said occupations; for example, the word for “nurse” almost always appeared in its feminine version, while “director” almost always appeared in its masculine version. In conclusion, corpus-based frequency analyses of online language use can provide insight into gendered biases in language.
Introduction
The topic of this paper is the use of gendered language in Turkish, which is a mostly gender-neutral language. This is studied through a corpus of Twitter texts containing both tweets and profile information. Twitter was chosen because it is a relatively good textual representation of more casual spoken language, or the language that people use in everyday conversation. The research questions are the following:
- How frequently is gender overtly expressed in the Turkish language in Twitter content?
- In what Twitter contexts (tweets, usernames, profile descriptions) are different gendered terms used and what might that indicate?
- What might the results of the first two questions indicate about Turkish culture in relation to gender?
The expression of gender in gender neutral languages can be enlightening, as it shows the purposeful choices people make when referring to gender. Research on gender in Turkish is sparse, with the main researcher being Friederike Braun, who is referenced throughout the paper. She has found that despite the mostly gender-neutral nature of Turkish, speakers still tend to assign genders to people according to gender stereotypes, and that gender is more often overtly expressed if the person referred to is female or differs from what the expected gender would be according to stereotypes. A corpus-based study of gendered language use in everyday conversation in Turkish has not been conducted before.
The method used in this research is a quantitative corpus analysis, in which frequencies of gender-neutral and gender-specific terms of person reference are analysed in both tweets and profile information. The structure of this paper is as follows: chapter 1 will focus on theory about gender in language in general and in Turkish specifically; chapter 2 will focus on research done on social media language; chapter 3 will go over the results of the quantitative research and analyse it according to the theory.
Chapter 1: Gender in language
Gender is and has been throughout history one of the most important social categories in human societies. Gender is also one of the most typical grammatical categories. Most Indo-European languages, for example, use grammatical gender to categorise and describe nouns: nouns are either feminine, masculine or, in some languages, neutral. This grammatical categorisation is usually not directly related to gender as a social category (e.g. there is nothing strictly feminine about bridges (German: die Brücke) or masculine about tables (German: der Tisch), while girls (German: das Mädchen) are not gender-neutral); however, certain evidence has been found for the influence of linguistic gender categorisation on societal gender norms and relations. For example, research conducted by Jakiela and Ozier (2018) found that societies that use gendered languages consistently display lower female labour force participation. Gendered language was also associated with more sexist attitudes towards women. The effects of grammatical language on gender in society are an issue that still needs further studying.
On the other hand, there are languages which do not use gender as a grammatical categorisation. These include many Turkic languages, such as Turkish. A gender-neutral language does not necessarily mean a gender-neutral society — gender can definitely be considered an important social categorisation in Turkish society. When the grammar of a language is genderless, gender can still be marked semantically by adding gendered lexemes to genderless words and phrases (this is also often done in English, e.g. the words boyfriend/girlfriend). In fact, gender-neutral grammar may make it easier to judge the importance of gender in a society; while in languages with grammatical gender, a speaker often has no choice as to whether or not they mark a person’s gender, in genderless languages the marking of gender is more often done optionally and purposefully. This may show us how important speakers consider marking a person’s gender, which can give us an idea of how important gender is to them in general. Grammatically genderless languages can be analysed to gain an idea of the importance of gender in society.
1.1 Turkish as a gender neutral language
Turkish is a language of the Turkic language family spoken primarily in Turkey. Unlike most Indo-European languages, Turkish is a language in which gender is not necessarily expressed when referring to people. All Turkish pronouns are gender-neutral (e.g. o meaning ‘he/she/it’) and most nouns referring to people carry no gender markings (e.g. kardeş ‘sibling’). Neither do verbs or adjectives. There are some common words that carry gendered meanings, especially among kinship terms and terms of address, but these are an exception rather than a rule among Turkish terms for person reference. There are certain gendered suffixes Turkish has borrowed from other languages; however, these suffixes typically only occur in the words they were borrowed with (e.g. the ending -içe, borrowed from Slavic, is used in words also borrowed from Slavic such as kraliçe ‘queen’). There are no productive gender-indicative suffixes in Turkish. Therefore, Turkish can be considered a relatively genderless language in terms of grammar. (Braun 2001)
This does not mean Turkish people do not find ways to refer to gender when speaking about other people. Gender is, after all, an important social category in Turkish society. Gender marking is usually achieved by combining gendered lexemes with gender-neutral terms for person reference. Common examples include kız kardeş ‘sister’ (literally: ‘girl sibling’) and erkek arkadaş ‘boyfriend’ (literally: ‘man friend’). When a speaker wants to refer to someone’s gender, they must do it explicitly, unlike in languages where adding a gender marking to most nouns referring to people is necessary. (Braun 2001)
1.2 Overt references to gender in language
In the case of a language like Turkish, the way people use language to overtly indicate a person’s gender can be an indicator of the Turkish gender belief system (Deaux 1985), as it shows how and when language users feel it is necessary to point out a person’s gender. This helps us understand the gender norms and stereotypes of the culture — for example, are Turkish people more likely to overtly indicate the gender of a person of a certain profession if they are female or male? Or, if gender is found to be more frequently marked when referring to females than males, this would indicate maleness being a kind of default that needs no mentioning, while femaleness is a special case that needs to be brought up.
This seems to be precisely the case with Turkish. A series of studies reported by Braun (2001) found that in general, maleness is the default category of humans while femaleness is a special case that is more frequently overtly marked. When it comes to certain contexts, such as professions or actions, overt gender markings very clearly display gender stereotypes and norms; for example, police and actions related to sports had a default attribute to maleness, while secretaries or cooking were automatically considered to be female domains. In cases that go against the stereotype, they are more likely to make overt reference to the gender of the person. (Braun 2001) This indicates that gender stereotypes for certain activities and occupations have a strong influence in Turkish society. Through the use of gendered language, we can find indications of the gender belief system and its strength in Turkish culture.
Gender is one of the most important social categories in most modern societies, including Turkey. Gender is also one of the most common grammatical categories in languages, which may have an effect on society in relation to gender. When it comes to gender-neutral languages like Turkish where gendering people and activities is not necessitated by the language, studying the choices speakers make to use explicitly gendered vocabulary can give us more of an insight into how important gender is in their culture. Braun (2001) has found, for example, that Turkish speakers are more likely to overtly mark gender when referring to women or participants in activities that go against the stereotype of their gender. This shows that the study of gendered language use in Turkish can indicate the nature and importance of gender and gender beliefs in Turkish society.
Chapter 2: Social media language
With the emergence of social media, the amount of linguistic data available on the Internet exploded, leading to the popularisation of using social media content in research. Twitter is one such social media platform that is frequently used in research. Twitter content is relatively easy to obtain through the Twitter API, comes with a good amount of metadata, and content is easy to analyse as the 280 character limit means all tweets are of a similar length and hashtags help to categorise content by topic. Twitter also supports 34 different languages, including Turkish, making it easy to filter content according to language.
Social media texts come with their own unique difficulties as well, the main one being language use. Social media language is often filled with typing and grammar errors, shortened forms and other non-standard spellings. Shortened forms of words tend to be especially common on Twitter due to the character limit. Languages with special characters, such as Turkish, are often written using only basic Latin alphabet characters (e.g. teşekkürler ‘thanks’ may be written tesekkurler). When mining social media for data, one must also be ready to see spam content in their data and decide whether to include it in their analysis or not.
Social media is a unique medium for textual content that can be very useful to analyse in various fields including linguistics. This chapter aims to explain the choice of using Twitter data for this particular research and the kind of insight it will hopefully provide. It will also give some background information on the use of Twitter in Turkey.
2.1 Tweets as a textual representation of emotional, natural spoken language
Computer mediated language (CMC) characteristically tries to imitate spoken language (along with body language, e.g. via emoji) through a text-based medium in order to get messages across in a way that is informal, simple and naturally understandable to the reader. Many interesting features have developed in CMC to do this. As found by Bieswanger (2013), among the first to describe some of these features was Murray (1988: 11), who listed textual CMC conventions such as “multiple vowels to represent intonation contours (e.g., “sooooo”)”, “use of asterisks for stress (e.g., “please call – we’ve *got* to discuss”)” and emoticons. Bieswanger also refers to another list of “common features for digital writing” proposed by Danet (2001: 17): multiple punctuation, eccentric spelling, capital letters, asterisks for emphasis, written out laughter, descriptions of action, “smiley” icons, abbreviations, and the use of all lower case. Nearly two decades later, all of these characteristics can still be commonly found in online texts. The purpose of these features is mainly to express emotion, intonation, accent and other natural parts of speech that are otherwise difficult to express through text.
This makes computer-mediated language in an informal online environment such as Twitter a relatively good indicator of people’s natural language use, unencumbered by the norms and pressures of more formal written language. An analysis of gender expression in Twitter content should give a good idea of how often people who use Twitter in Turkish think about and use gendered language in general. Of course, there are still many factors that can skew results, such as people trying to create a certain online image for themselves through language use, the existence of official accounts that may purposefully use more neutral or politically correct language and people using various non-standard forms of words that are difficult to find with the given research method. Some of these limitations can be decreased, e.g. by filtering out tweets posted by verified official accounts. In conclusion, Twitter can give us insight into natural language use that many other written text mediums cannot.
2.2 Importance of social media profiles and usernames in personal identity
Other than tweets, Twitter data also includes the usernames and profiles of users. A Twitter user must have a username up to 15 characters long, made up of basic Latin alphabet letters, numbers and underscores. The username is used for logging in, linking to an account and writing direct tweets or messages to a user. Users can also have a name, which can consist of up to 50 characters of any type (different scripts, symbols, emojis etc are allowed). Users can also write a profile description of up to 160 characters. These are the main freeform textual elements that a Twitter user’s profile is made up of.
While tweets can often refer to and describe other people, username and profile data can give us direct insight into how the user sees or chooses to present themselves. As Lindholm (2013) describes, research has found that online usernames are often used to present aspects of identity such as gender, race, physical attributes and interests (Bays 1998, Campbell 2004, Stommel 2007). She also found research showing that usernames influence how users perceive each other (Byrne 1994; Chester and Gillian 1998; Jacobson 1999). Whether a user encounters another user through a retweet on their timeline or Twitter’s “Who to follow” suggestions in the sidebar, their name and username will always be one of the first things they see. If they click onto their profile, the next things they will see are their description, location and (if given) a link, usually to their website or account on another social media platform such as Instagram. Therefore, constructing an identity through their profile is important in order to seem attractive to certain types of people and encourage them to follow and interact with an account.
The following word clouds display differences between vocabulary use in tweets and profile descriptions according to the corpus created for the current research paper, which support many of the previous claims:


These word clouds demonstrate a significant difference between tweets and descriptions, as tweets contain more general language describing actions, states of being and other people and things. Descriptions contain more self-descriptive language, such as favourite football teams, important public figures and universities. The large amount of English in descriptions is also interesting, and can mostly be attributed to English quotes used in profile descriptions (examples: “Feel the fear and do it anyway”, “Be yourself”), but also to people writing their descriptions in English in order to be understood by a wider audience, even if the majority of their tweets are written in Turkish. The different purposes and aims of tweets and profile content create differences in the language use, especially when it comes to vocabulary.
As gender is one aspect of identity that can be expressed through user information, it is interesting to analyse how this is done. Is it more common for men or women to indicate their gender? What different types of words do they use to do this (e.g. “man” vs “boy”, “woman” vs “girl”)? How often do men and women use masculine or feminine forms of terminology such as kinship terms or occupational titles to describe themselves? The prevalence of these gendered terms can give an indication of how important gender is in the social construction and identity of Turkish Twitter users.
2.3 Who uses Twitter in Turkey?
When analysing Twitter data, it is useful to keep in mind who the main demographics using Twitter are, as those are the people being analysed. Generally, social media users are young on average and more commonly urban. Political context is also relevant in Turkey when it comes to social media.
According to Statista (Clement 2019), Turkey is 6th in the world by amount of Twitter users, with 8.33 million active users as of October 2019. That’s nearly 10% of the population. Little data is available about Turkish Twitter usage specifically. Polat and Tokgöz (2014) found that out of 63 Twitter users participating in their research, a little over half were men (58%) and 61% of participants were from Istanbul, with the other 39% being evenly split between Ankara, Izmir and “other”. Age groups varied, with most being between 18 and 40 years of age.
A report by Dogramaci and Radcliffe (2015) describes the spread and use of social media in Turkey. Only about half the population has access to the Internet, with most of them being in large Turkish cities. It was found that 67% of people in urban Turkey use social media as a news source, which is considerably higher than average. This can be explained by general distrust of traditional media in Turkey. Twitter is the second most popular social media platform, with Facebook being the first. 33% of Turkish Twitter users use Twitter as a news source. Other popular uses for Twitter included entertainment, sports, lifestyle and following personalities such as singers, celebrities and politicians. When speaking of social media in Turkey, it is also important to note that multiple social media platforms including Twitter have been blocked by the Turkish government in recent years due to circulation of content deemed offensive to Turkey. In April 2015, Twitter was blocked along with Facebook and Youtube for circulating a picture of a Turkish prosecutor held at gunpoint. Turkey also commonly requests content removal from social media platforms; in 2014, Turkey was the country that sent the most requests for content removal to Twitter. However, the blockings and censorship have not been found to have a significant influence on social media usage in Turkey.
There is no freely available data on age or gender demographics among Turkish Twitter users. As for worldwide statistics, about 63% of Twitter users are between 35 and 65 years old according to Obero (Lin 2019). Only a third of Twitter users are female, according to a report published on We Are Social (Kemp 2019). This makes the average Twitter user a middle-aged male. We can assume that Turkish Twitter users do not differ too significantly from the global statistics, but without data we cannot be sure.
Social media texts can be useful research materials, as they offer a large amount of textual data and metadata for analysis. Due to the nature of social media language, insight can be gained into casual everyday language through this data. Twitter textual data can be divided into two parts: tweet content and profile content. Tweets can have various aims and subjects, and tend to match more closely the everyday conversational language use. Profile descriptions, names and usernames are written in order for a user to present themselves. They tend to contain more specific vocabulary used to describe the user’s life and interests. Twitter is the second most popular social media platform in Turkey and is mostly used by people living in large urban cities for news and entertainment. Data on age and gender demographics could not be found.
Chapter 3: Corpus analysis of Turkish tweets
3.1 Technical details
A corpus of 107,990 Turkish tweets was made using R in RStudio using the twitteR package (Gentry 2015). The following R code was used to gather the tweets:
turkish <- search_tweets("lang:tr", include_rts = FALSE, include_verified = FALSE, n=100000, retryonratelimit = TRUE)
The tweets were gathered on 25.09.2019, with timestamps between 13:53 and 14:41. Retweets were not included, in order to get a wider range of different tweets. Verified accounts were not included as they have a tendency to use more formal language and the purpose of the corpus is to research informal social media language.
From the resulting data table, separate tables were made of the content of the tweets, the usernames of the tweeters, their display names and their profile descriptions. The table of tweets was cleaned of hyperlinks and direct @-mentions. Then, separate corpora were made using Sketch Engine, an online programme for creating and analysing corpora, for tweet content and profile descriptions (found at http://www.sketchengine.eu). The tweet corpus contained a total of 1,288,712 tokens, the description corpus contained 507,785 tokens, profile names contained 122,852 tokens and usernames were each one token, with 67,541 of them in total.
The corpora were searched for words starting with the stems of a chosen list of female-describing, male-describing and gender-neutral terms for person reference using the ‘Wordlist’ function on Sketch Engine, which returns a list of all terms matching the search request in order of frequency. The search was done for words starting with the stems as Turkish is an agglutinative language that uses suffixes, so finding all words starting with the stem allowed for all of its inflected forms to be counted as well. Certain misspellings were also included in the search, in which Turkish special characters (ı, ü, ğ, ş, ö, ç) were replaced with the basic Latin alphabet equivalent. Words ending with k were also searched for their inflected form, in which k is replaced by ğ (e.g. erkek ‘man’ was also searched as erkeğ and erkeg). The words matching the correct stem were counted. In the case of ambiguities (e.g. certain inflected forms of a stem that is similar to a different stem, such as kız ‘girl’ and kızmak ‘to be angry’, may have more than one meaning), the contexts of the words were checked using the “Concordance” function and only instances with the correct meaning counted. Names and usernames were simply analysed using the Search function in RStudio, in which the stem was searched and all relevant instances counted.
3.2 Findings
The aim of this corpus analysis is to find frequencies of different gendered and gender-neutral terms of person reference used in both tweet content and Twitter profile content, in order to gain an idea of how often gendered language is used as opposed to gender-neutral language, and of which words are used. Findings will be displayed as four separate tables: one for general terms of person reference (e.g. “person”, “woman”) in tweets, one for specific terms of person reference (such as occupational titles) in tweets, one for general terms of person reference in profile content and one for specific terms of person reference in profile content.
|
Term |
Meaning |
Gender referenced |
Frequency in tweets |
|---|---|---|---|
|
İnsan |
Person |
Neutral |
4,197 |
|
Kişi |
Person |
Neutral |
1,396 |
|
Kimse |
Someone |
Neutral |
1,271 |
|
Kadın |
Woman |
Female |
1,207 |
|
Kız |
Girl/daughter |
Female |
1,425 |
|
Bayan |
Woman |
Female |
324 |
|
Hanım |
Woman |
Female |
309 |
|
Erkek |
Man |
Male |
634 |
|
Oğlan |
Boy/son |
Male |
50 |
|
Oğul |
Boy/son |
Male |
29 |
|
Adam |
Man/person |
Male/Neutral |
2,169 |
Table 1 shows frequencies of gender-neutral, female referencing and male referencing general person reference terms in tweets. The various gender-neutral terms denoting ‘person’, ‘human’ or ‘someone’ had the largest frequencies, indicating that people talk about ‘people’ in general more often than they do about specifically men or women.
When comparing the gendered terms such as ‘man’ and ‘woman’, terms referring to females were much more common than those referring to men. Adam is an exception, as it is a term that can be both male-specific as well as generally referring to people. This finding is supported by other research such as Braun’s that shows people are more likely to specify gender if they are talking about a woman than a man.
Another interesting finding is the frequency of kiz, meaning ‘girl’. This is the most frequent out of all the female referencing terms, while terms meaning ‘boy’ had very low frequency. The phenomenon of women being referred to as ‘girls’ has been found in many languages including English, and can be considered an example of the infantilisation of women in patriarchal society (Huot 2013).
It is important to note that hanım and oğul are also found in Turkish names, which the analysis was not able to fully account for.
|
Term |
Meaning |
Gender referenced |
Frequency |
|---|---|---|---|
|
Müdür |
Director |
Neutral/male |
355 |
|
Müdire |
Director |
Female |
0 |
|
Sahip |
Owner |
Neutral/male |
394 |
|
Sahibe |
Owner |
Female |
10 |
|
Memur |
Officer |
Neutral/male |
90 |
|
Memure |
Officer |
Female |
1 |
|
Imparator |
Emperor |
Male |
40 |
|
Imparatoriçe |
Empress |
Female |
0 |
|
Aktör |
Actor |
Neutral/male |
9 |
|
Aktris |
Actress |
Female |
0 |
|
Prens |
Prince |
Male |
14 |
|
Prenses |
Princess |
Female |
33 |
|
Kral |
King |
Male |
271 |
|
Kraliçe |
Queen |
Female |
39 |
|
Hemşir |
Nurse |
Male |
0 |
|
Hemşire |
Nurse |
Female |
22 |
|
Host |
Host |
Male |
0 |
|
Hostes |
Hostess |
Female |
4 |
|
Rahip |
Priest/monk |
Male |
4 |
|
Rahibe |
Priestess/nun |
Female |
1 |
|
Damat |
Groom |
Male |
35 |
|
Gelin |
Bride |
Female |
136 |
|
Hakim |
Judge |
Neutral/male |
100 |
|
Hakime |
Judge |
Female |
4 |
Table 2 shows frequencies of more specific person reference words, mostly describing occupations, which have separate male and female forms. Most of these words are of Arabic or Latin origin; Turkish occupation names are otherwise gender-neutral. The exception is gelin, meaning ‘bride’.
In almost all cases, the male version had a significantly higher frequency, with many female versions having a frequency of 0. This may be because the male version is often also used as a gender neutral version, and does not always necessarily refer to a man. The only terms that were more frequent in the female version were those meaning ‘princess’, ‘nurse’, ‘hostess’ and ‘bride’, which are occupations and activities stereotypically assigned to women. ‘Princess’ was found to be often used as a compliment or term of endearment towards women.
It is worth noting that sahibe, the female version of ‘owner’, was mostly used in a sexual context in reference to sexual dominatrices by so-called ‘porn bots’ which are spam accounts that post sexually explicit content, usually with the aim of advertising adult websites.
The next two tables show frequencies of the same terms of person reference in Twitter usernames, names and descriptions. As the numbers of unique usernames, names and descriptions in the corpus were different (67,541 usernames, 58,902 names, 50,759 descriptions), the frequencies have been modified to show frequency per 100,000 words, rounded to the second decimal point (raw data tables can be found in Appendix A and B).
|
Term |
Frequency per 100,000 in usernames |
Frequency per 100,000 in names |
Frequency per 100,000 in descriptions |
Total |
|---|---|---|---|---|
|
İnsan |
66.63 |
42.44 |
2915.74 |
3,024.81 |
|
Kişi |
31.09 |
30.56 |
900.33 |
961.98 |
|
Kimse |
17.77 |
16.98 |
598.91 |
633.66 |
|
Kadın |
51.82 |
88.28 |
699.38 |
839.48 |
|
Kız |
149.54 |
156.19 |
470.85 |
776.58 |
|
Bayan |
42.94 |
44.14 |
397.96 |
485.04 |
|
Hanım |
68.11 |
88.28 |
137.91 |
294.3 |
|
Erkek |
23.69 |
61.12 |
413.72 |
498.53 |
|
Oğlan |
17.77 |
22.07 |
21.67 |
61.51 |
|
Oğul |
44.42 |
67.91 |
13.79 |
126.12 |
|
Adam |
230.97 |
307.29 |
604.82 |
1,143.08 |
Most words have significantly higher frequencies in descriptions than usernames and names, which can largely be explained by the simple fact that the character limit in descriptions is larger and more words are used in them, while names and usernames often simply involve the person’s real name. The most common gendered words used in usernames and names are kız and adam, which may indicate that these are words people will most readily associate themselves with.
It is interesting to note that in descriptions, kadın is more common than kız, unlike in tweet content. As tweets are more commonly written to also refer to other people and descriptions generally refer to the person writing, this may indicate women are more likely to refer to themselves as ‘woman’ rather than ‘girl’. However, considering the relative frequency of kız in names and usernames, this needs further research.
|
Term |
Frequency per 100,000 in usernames |
Frequency per 100,000 in names |
Frequency per 100,000 in descriptions |
Total |
|---|---|---|---|---|
|
Müdür |
0 |
52.63 |
301.42 |
354.05 |
|
Müdire |
0 |
0 |
1.97 |
1.97 |
|
Sahip |
5.92 |
5.09 |
153.67 |
164.68 |
|
Sahibe |
8.88 |
8.49 |
17.73 |
35.1 |
|
Memur |
5.92 |
5.09 |
63.04 |
74.05 |
|
Memure |
0 |
0 |
0 |
0 |
|
Imparator |
2.96 |
6.79 |
31.52 |
41.27 |
|
Imparatoriçe |
0 |
0 |
0 |
0 |
|
Aktör |
0 |
0 |
3.94 |
3.94 |
|
Aktris |
0 |
0 |
1.97 |
1.97 |
|
Prens |
10.36 |
13.58 |
21.67 |
45.61 |
|
Prenses |
17.77 |
30.56 |
59.10 |
107.43 |
|
Kral |
82.91 |
81.49 |
153.67 |
318.07 |
|
Kraliçe |
14.81 |
18.68 |
37.43 |
70.92 |
|
Hemşir |
2.96 |
3.40 |
3.94 |
10.3 |
|
Hemşire |
8.88 |
8.49 |
175.34 |
192.71 |
|
Host |
0 |
0 |
11.82 |
11.82 |
|
Hostes |
0 |
0 |
7.88 |
7.88 |
|
Rahip |
1.48 |
0 |
0 |
1.48 |
|
Rahibe |
1.48 |
0 |
0 |
1.48 |
|
Damat |
1.48 |
3.40 |
11.82 |
16.7 |
|
Gelin |
5.92 |
11.88 |
80.77 |
98.57 |
|
Hakim |
8.88 |
13.58 |
53.19 |
75.65 |
|
Hakime |
4.44 |
0 |
0 |
4.44 |
Terms like hemşir (male nurse) and host (male host) occur more frequently in Twitter profiles than in tweets, in which they both had 0 frequencies. However, host only occurs in Twitter descriptions written in English, mostly in the context of being a TV host. This indicates the word is not used in Turkish, while hostes is. There seems to be slightly more variance in male and female gendered terms, as many terms that had 0 frequency in tweets now have frequencies above 0.
3.3 Discussion
Generally, the results were not surprising as the matched research done by Braun and generally expected gender stereotypes. Results will be illustrated with graphs.
Graph 1 displays the overall frequencies of gender-neutral, feminine, masculine and neutral/masculine general and specific terms in tweets and profile content.
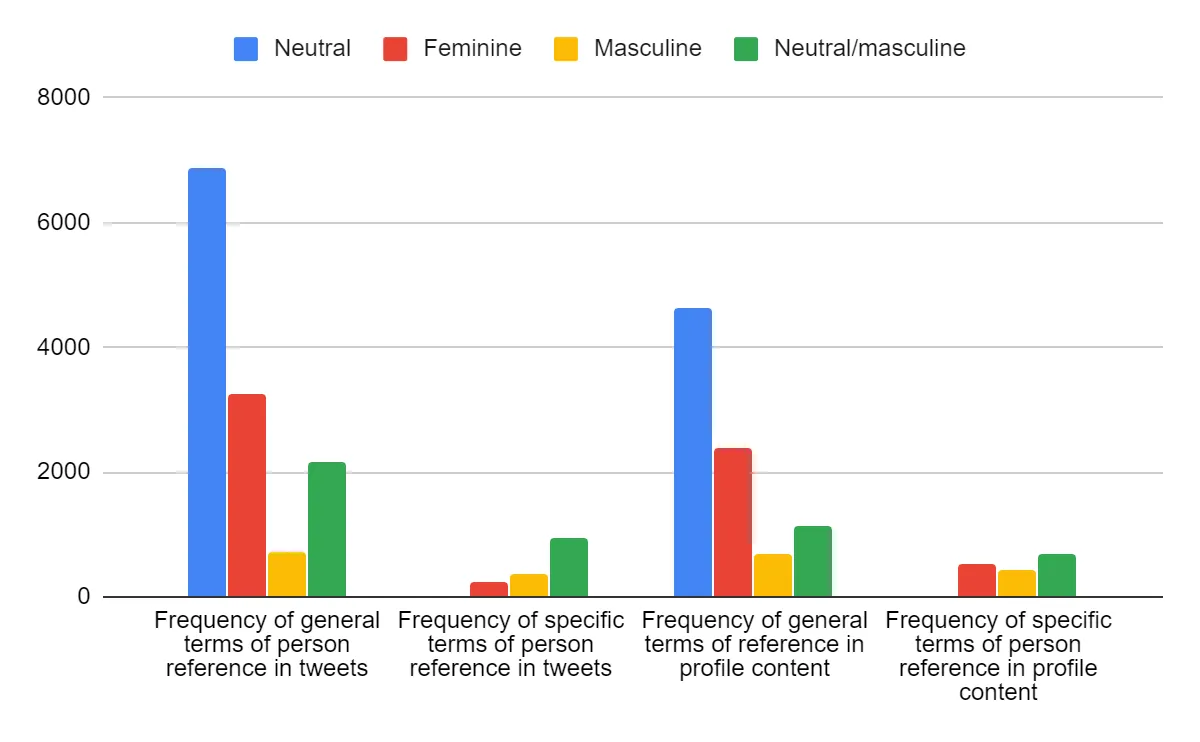
Gender-neutral terms were used most often, both in general terms of person reference and specific terms of person reference, if we consider most of the masculine occupation words (those marked ‘Neutral/masculine’) also gender-neutral. This may indicate gender is not necessarily that important to Turkish Twitter users, who will commonly refer to a person as simply “a person” without thinking of gender. However, out of the gendered terms, female terms were significantly more frequent among general terms of person reference. This supports Braun’s findings that femaleness is more commonly overtly marked as a special case, while maleness is the default.
It is interesting to note that the word for ‘girl’ was by far the most frequent feminine general term in tweets, while ‘boy’ was barely used at all. This indicates the word ‘girl’ being used when referring to women, which is a common trend in English as well (Huot 2013). This linguistic phenomenon is often treated as part of a more general societal trend to infantilise women, which also includes stereotypically applying infantile traits such as helplessness and vulnerability to women. When we look more closely at feminine general terms of reference, it is interesting to note the differences in profile contents as well:
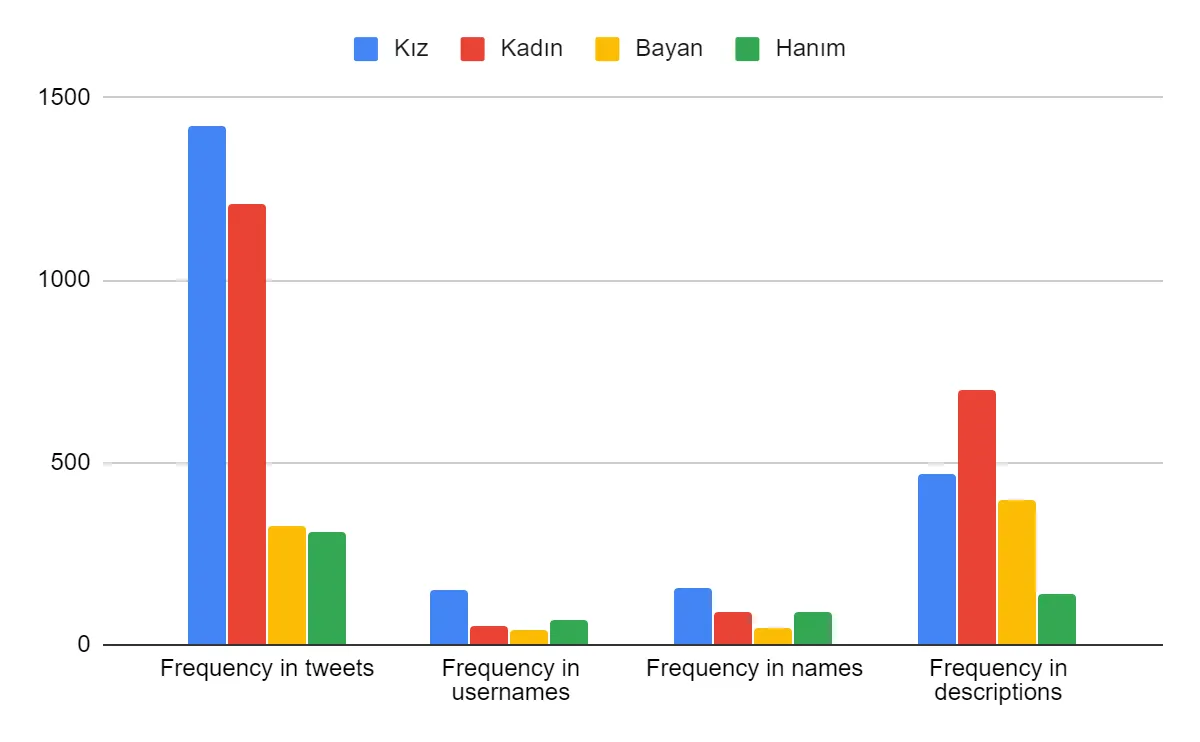
While tweets often refer to other people, usernames and descriptions are generally written to refer to oneself. In both usernames and names, ‘girl’ is the second most common word after adam (person/man). This indicates a tendency of women to use the same language of infantilisation to refer to themselves as well. In descriptions, however, kadın ‘woman’ is significantly more frequent, indicating the opposite: women prefer to refer to themselves as women. The phenomenon of infantilisation of women through language in Turkey is a topic that requires further research.
As for specific terms of person reference, the masculine versions were nearly always significantly more frequent in both tweets and profiles, with many feminine versions not occurring at all. This can be largely explained by the fact that the masculine versions are also often used as gender-neutral terms. However, gender stereotypes seem to also have an influence, as the few terms that were more frequent as the feminine version were terms stereotypically assigned to women. Feminine versions of specific terms had slightly higher frequency in profile content than in tweets, indicating that women who themselves identify with these terms are more likely to describe themselves using the feminine versions of these terms than people in general are of using them to describe others.
In conclusion, gender-neutral terms are the most frequent out of the terms of reference, especially if we consider many of the masculine specific terms of person reference gender-neutral. Among gendered general terms, female terms were more common, suggesting further evidence for the theory that femaleness is more often considered worth mentioning while maleness is a default. Among specific terms, female terms were only common in occupations stereotypically associated with women such as ‘nurse’ and ‘princess’. These findings show evidence that Turkish speakers’ language use is influenced by gender norms and stereotypes.
In this chapter, a corpus of over 100,000 tweets and their corresponding Twitter profiles was created and analysed using Sketch Engine. The frequencies of gendered and non-gendered terms were found and gathered into separate tables for general and specific terms of person reference and tweet and profile content. The results show a strong preference for gender-neutral terms, both in general and specific terms. When comparing gendered general terms of person reference, many of the theories mentioned previously are supported: femaleness is more commonly specified when it comes to general terms of reference, while among occupation-words feminine terms were most frequent in those occupations stereotypically female. This suggests a more frequent marking of femaleness as a ‘special case’ as well as a prevalence of gender norms and stereotypes and their influence on the Turkish language. Data was interestingly conflicting on the use of kız, and the linguistic infantilisation of women in Turkish is a topic that requires further research.
Conclusion
The research questions of this paper were the following:
- How frequently is gender overtly expressed in the Turkish language on Twitter?
- In what Twitter contexts (tweets, usernames, profile descriptions) are different gendered terms used and what might that indicate?
- What might the results of the first two questions indicate about Turkish culture in relation to gender?
In regards to the first question, I found that gender-neutral terms of person reference are used most frequently in both tweets and profile content. Out of the gendered terms, feminine general terms of person reference are used significantly more frequently than masculine ones, while for specific terms of person reference the opposite is true. Female specific terms were only more frequent for those describing stereotypically female occupations.
In regards to the second question, the most interesting difference was found in regards to the word kız ‘girl’, which was the most frequent feminine term in tweets, names and usernames but was surpassed by kadın ‘woman’ in profile descriptions. This could indicate the pervasive use of ‘girl’ when referring to women by others, but a greater willingness to use ‘woman’ when describing oneself. Feminine versions of specific terms also had a generally slightly higher frequency in profile content than tweets, indicating that women are more likely to use these terms to refer to themselves than people in general are to others.
As for the third question, my results showed a general preference for gender-neutrality which could indicate a lower importance given to gender in society (or at least, to urban society). It also, however, gave support to the prevalence of certain gender stereotypes, the idea of maleness as the default and the phenomenon of infantilisation of women.
To answer these questions, a corpus analysis of over 100,000 tweets and their corresponding Twitter profiles was done using Sketch Engine to find frequencies of lists of gendered and gender-neutral terms of person reference. This was chosen as a method because tweets are a textual source offering relatively good insight to casual, everyday spoken language that is freely available and comes with metadata that offered extra insight into how people choose to describe themselves in their social media profiles.
This is the first quantitative research that has been done to analyse the use of gendered language in informal Turkish. Gender in Turkish is a topic that has been researched very little thus far, with the most significant body of work written by Friederike Braun.
References
Bays, Hillary. 1998. Framing and face in Internet exchanges: A socio-cognitive approach. Linguistik Online 1(1).
Bieswanger, Markus. 2013. Micro-linguistic structural features of computer-mediated communication. Pragmatics of Computer-Mediated Communication; pp 463-485. Herring, Susanna et al. ed. De Gruyter Inc.
Braun, Frederieke. 2001. The communication of gender in Turkish. Gender Across Languages 1; pp 283-310. Hellinger, Marlis & Bußmann, Hadumond ed. John Benjamins Publishing Company: Amsterdam/Philadelphia.
Byrne, Elizabeth. 1994. Cyberfusion: the formation of Internet relationships on Internet Relay Chat. Ph.D. dissertation, Faculty of Humanities and Social Sciences, University of Western Sydney.
Campbell, John E. 2004. Getting it on Online: Cyberspace, Gay Male Sexuality, and Embodied Identity. Haworth: New York.
Chester, Andrea; Gillian, Gwynne. 1998. Online teaching: Encouraging collaboration through anonymity. Journal of Computer-Mediated Communication 4(2).
Clement, J. Countries with the most Twitter users 2019. Nov 20, 2019. Statista. https://www.statista.com/statistics/242606/number-of-active-twitter-users-in-selected-countries/ (08.01.2020).
Danet, Brenda. 2001. Cyberpl@y: Communicating Online. London: Berg.
Deaux, Kay. 1985. Sex and gender. Annual Review of Psychology 36: pp 49–81.
Dogramaci, Esra; Radcliffe, Damian. 2015. How Turkey Uses Social Media. Digital News Report. http://www.digitalnewsreport.org/essays/2015/how-turkey-uses-social-media/ (08.01.2020).
Gentry, Jeff. 2015. twitteR: R Based Twitter Client. R package version 1.1.9. https://CRAN.R-project.org/package=twitteR (27.02.2020).
Jacobson, David. 1999. Context and cues in cyberspace: the pragmatics of naming in text-based virtual realities. Journal of Anthropological Research 52(4): pp 461-479.
Jakiela, Pamela; Ozier, Owen. 2018. Gendered language (English). Policy Research working paper; no. WPS 8464. Washington, D.C. : World Bank Group. http://documents.worldbank.org/curated/en/405621528167411253/Gendered-language (08.01.2020).
Lin, Ying. 10 Twitter Statistics Every Marketer Should Know in 2020 [Infographic]. 30 Nov, 2019. Oberlo. https://www.oberlo.com/blog/twitter-statistics (08.01.2020).
Lindholm, Loukia. 2013. The maxims of online nicknames. Pragmatics of Computer-Mediated Communication; pp 437-462. Herring, Susanna et al. ed. De Gruyter Inc.
Murray, Denise E. 1988. Computer-mediated communication: Implications for ESP. English for Specific Purposes 7; pp 3-18.
Polat, Burak; Tokgöz, Cemile. 2014. Twitter User Behaviors In Turkey: A Content Analysis On Turkish Twitter Users. Mediterranean Journal of Social Sciences 5(22). http://bit.ly/1LYIeSq (08.01.2020).
Stommel, Wyke. 2007. Mein Nick bin ich! [My nickname is me!] Nicknames in a German forum on eating disorders. Journal of Computer-Mediated Communication 13(1), article 8.
Appendix
|
Term |
Freq. in usernames |
Freq. in names |
Freq. in descriptions |
Total |
|---|---|---|---|---|
|
İnsan |
45 |
25 |
1480 |
1550 |
|
Kişi |
21 |
18 |
457 |
496 |
|
Kimse |
12 |
10 |
304 |
326 |
|
Kadın |
35 |
52 |
355 |
442 |
|
Kız |
101 |
92 |
239 |
432 |
|
Bayan |
29 |
26 |
202 |
257 |
|
Hanım |
46 |
52 |
70 |
168 |
|
Erkek |
16 |
36 |
210 |
262 |
|
Oğlan |
12 |
13 |
11 |
36 |
|
Oğul |
30 |
40 |
7 |
33 |
|
Adam |
156 |
181 |
359 |
696 |
|
Term |
Freq. in usernames |
Freq. in names |
Freq. in descriptions |
|---|---|---|---|
|
Müdür |
0 |
31 |
153 |
|
Müdire |
0 |
0 |
1 |
|
Sahip |
4 |
3 |
78 |
|
Sahibe |
6 |
5 |
9 |
|
Memur |
4 |
3 |
32 |
|
Memure |
0 |
0 |
0 |
|
Imparator |
2 |
4 |
16 |
|
Imparatoriçe |
0 |
0 |
0 |
|
Aktör |
0 |
0 |
2 |
|
Aktris |
0 |
0 |
1 |
|
Prens |
7 |
8 |
11 |
|
Prenses |
12 |
18 |
30 |
|
Kral |
56 |
48 |
78 |
|
Kraliçe |
10 |
11 |
19 |
|
Hemşir |
2 |
2 |
2 |
|
Hemşire |
6 |
5 |
89 |
|
Host |
0 |
0 |
6 |
|
Hostes |
0 |
0 |
4 |
|
Rahip |
1 |
0 |
0 |
|
Rahibe |
1 |
0 |
0 |
|
Damat |
1 |
2 |
6 |
|
Gelin |
4 |
7 |
41 |
|
Hakim |
6 |
8 |
27 |
|
Hakime |
3 |
0 |
0 |